-
Created by
 Ivan Arkhipov, last updated on Jan 14, 2024
5 minute read
Ivan Arkhipov, last updated on Jan 14, 2024
5 minute read
О чём этот гайд
В этом документе описываются технологии, которые мы используем для написания бэкенд-части проекта (т.е. кода, который исполняется на сервере и отвечает за всю логическую работу: обработку данных, создание объектов и работу с базой данных, контроль за правами доступов, и т.д.).
Глоссарий
| Термин | Определение |
|---|---|
| Бизнес-логика | Набор правил (условий), которые описывают сущности внутри программы и их взаимодействие. По сути, это формальные "правила", по которым работает приложение |
| Бэкенд | Программная часть сервиса, которая работает на сервере (а не в браузере или на компьютере). Бэкенд отвечает за:
|
| Фронтенд | Программная часть сервиса, выполняющаяся в браузере пользователя (в противовес бэкенду). Задача фронтенда: отрисовывать интерфейс пользователя (страничку в браузере), реагировать на события интерфейса (нажатие кнопочек/переход между страницами/etc.) и взаимодействовать с бэкендом, запрашивая у него данные (или отправляя ему данные и получая результат операций) |
| Сервер (ПО) | Сервером будем называть программу (или набор программ), выполняющиеся на железяке в датацентре и обеспечивающую работу бэкенда сервиса. Т.е. когда в тексте встречаются "отправляем данные на сервер" или "взаимодействуем с сервером", по сути речь идёт о программах (бэкенд-составляющей сервиса) |
| Клиент (ПО) | Клиентом будем называть браузер пользователя (т.е. программу, обеспечивающую отрисовку интерфейса и взаимодействующую с сервером для получения данных) |
Основные концепции
Сайт mipt.tech исповедует жесткое разделение на backend- и frontend-составляющие, которые взаимодействуют между собой по протоколу REST API.
Кратко работу протокола иллюстрирует следующая картинка (с тем лишь исключением, что в нашем случае REST API предоставляет сервер на Python, а клиентом - Application выступает браузер и приложение на NextJS/Typescript).
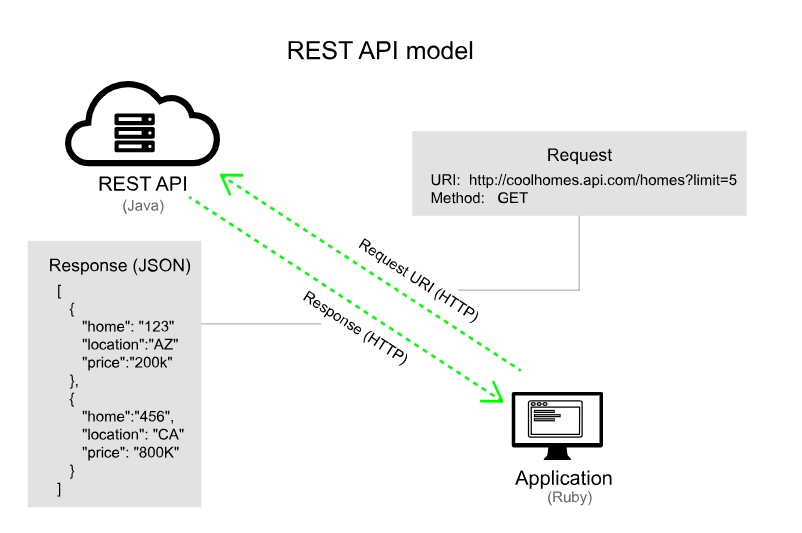
Для полноценного понимания, что такое REST API, настоятельно рекомендуется прочитать и понять следующую статью: https://cloud.yandex.ru/ru/docs/glossary/rest-api
Используемые технологии:
Веб-сервер:
Для работы бэкенда используется язык программирования Python (как наиболее оптимальный с точки зрения простоты/известности/скорости разработки) и фреймворк Django REST Framework (как наиболее удобный за счёт наличия большинства необходимых функций "из коробки", будь то работа с СУБД/авторизация/кеширование/фоновые задания и т.д.). Этот фреймворк позволяет быстро и эффективно "строить" веб-сервисы, использующие протокол REST API.
База данных и ORM:
Для хранения данных используется реляционная база данных PostgreSQL. При этом мы не пишем sql-запросы руками, вместо этого мы используем ORM (для ознакомления рекомендую эту статью) - фреймворк для работы с данными (конкретно мы используем ORM, включенную в библиотеку Django, она так и называется: Django ORM), который позволяет работать с сущностями, представленными в виде Python-классов и методами этих классов, вместо работы с таблицами БД и sql-запросами соответственно.
Например, для описания сущности "Фотография" и работы с этой сущностью мы будем использовать следующий код на Python:
from django.db import models
from accounts.models import User
class Photo(models.Model): # Модель == сущность. Каждой модели соответствует таблица в БД, которая создаётся автоматически на основе атрибутов класса
title = models.CharField(max_length=200) # Каждый атрибут класса фактически является колонкой таблицы в БД.
author = ForeignKey(User, verbose_name="Автор фотографии") # Отношения ()
# Получить все фотографии, имеющиеся в БД (одна фотография == 1 строка с таблице БД == один объект класса Photo)
# По сути эквивалент sql-запроса "SELECT * FROM photo_table;"
photos: List[Photo] = Photo.objects.all()
# Получить все фотографии, для которых название равно "my photo"
# Эквивалент запроса SELECT * FROM photo_table WHERE title="my photo";
photos: List[Photo] = Photo.objects.filter(title="my_photo")
# Вывести название всех фотографий, хранящихся в БД
for photo in Photo.objects.all():
print(photo.title)
# Создать новый объект фотографии
Photo.objects.create(title="New photo title", user=User.objects.get(username="admin"))
Мы очевидно взаимодействуем с базой данных, создавая/получая данные оттуда, но при этом не написали ни одного sql-запроса, а работаем с абстрактной сущностью (в дальнейшем "сущность" будем именовать "Моделью"). Для дальнейшего знакомства с Django ORM рекомендуется эта статья https://habr.com/ru/articles/503526/
Кэширование:
В дополнение к реляционной базе данных мы дополнительно используем in-memory (т.е. хранящую все данные в оперативной памяти) key-value (т.е. хранящую данные в виде ассоциативного массива ключ-значение) базу данных Redis. За счёт работы в оперативной памяти Redis является очень быстрым хранилищем, отлично подходящим для кэширования часто запрашиваемых данных, и хранения временной информации.
Фоновые задания:
И, наконец, ещё одна значимая область бэкенда - это фоновые задания. Обычно взаимодействие с пользователем происходит в формате "запрос-ответ": пользователь отправил запрос, бэкенд сходил в БД, достал данные и отдал их в ответе. Однако иногда в результате запроса требуется запустить какое-либо задание, окончания которого не нужно дожидаться "здесь и сейчас" - например, при бронировании стиральной машинки мы хотим отправить пользователю уведомление в ВК за 10 минут до начала бронирования. Для выполнения таких "фоновых" заданий требуется отдельный механизм.
Такой механизм предоставляет фреймворк Celery
По сути он позволяет с помощью специального декоратора объявить python-функцию как асинхронную задачу. Такую функцию можно вызывать как обычную функцию (тогда она будет выполняться в процессе Django в процессе обработки запроса пользователя), а можно вызывать как асинхронную - тогда django вместо прямого выполнения функции добавит сообщение о необходимости выполнить функцию в специальную очередь и "забудет". В качестве специальной очереди используется специальная база данных сообщений (она называется "брокер сообщений") RabbitMQ.
Итак, Django отправляет сообщения в RabbitMQ о том, что надо выполнить функцию. Django выступает в роли "Producer" - отправщика. А кто эту функцию по-факту выполняет?
Для выполнения асинхронных задач у нас запускаются отдельные программы - воркеры фоновых задач. Они спрашивают RabbitMQ о новых сообщениях, и при получении сообщения начинают выполнять указанную функцию.
Celery (фреймворк фоновых задач) написан также на Python и замечательно интегрируется с Django, позволяя использовать один и тот же код и на стороне отправителя сообщений (веб-сервера Django), и на стороне получателя сообщений (celery-воркера, обрабатывающего фоновые задания). Таким образом воркеры (в дальнейшем будем называть их Celery-воркеры, или консьюмеры/Consumers) - это такие же python-приложения, только запущенные с другими параметрами. Благодаря использованию одинаковой кодовой базы с веб-сервером, эти воркеры понимают, о какой именно функции "говорил" веб-сервер, и как её выполнять, избегая нас (разработчиков) от явного описания, как "отправитель" и "получатель" должны между собой взаимодействовать.
Архитектурно получается следующая картинка:

Для понимания всего вышесказанного настоятельно рекомендуется прочитать и понять следующую статью
Резюме
Для разработки бэкенд-части сервиса мы используем язык Python.
Работу веб-сервера и REST API обеспечивают библиотеки Django и Django-rest-framework
Для хранения данных мы используем реляционную БД PostgreSQL, а для кэширования и хранения часто меняемых/временных данных - Redis
Для работы с фоновыми задачами мы используем фреймворк Celery, а в качестве "транспорта" для передачи сообщений от веб-сервера к воркеру используем RabbitMQ